
TOPIC 9: Collectieve Datastructuren¶
Tot nu toe hebben we eigenlijk 2 soorten van data gezien:
Atomaire Data zoals gehele getallen, floating point getallen, complexe getallen, booleaanse waarden, strings, … zijn soorten data die we als ondeelbaar beschouwden in Python. Je kan weliswaar operatoren en functies op deze data toepassen maar we beschouwen die data doorgaans als zijnde “zonder interne structuur”.
Datastructuren daarentegen zijn “netwerken” van data die aan mekaar “gelijmd” zijn. Het zijn letterlijk structuren van data. De eenvoudigste voorbeelden die we hiervan gezien hebben zijn tupels en lijsten. De data die in zulke tupels en lijsten zit kan atomair zijn (getallen bijvoorbeeld). Maar het kunnen ook willekeurig ingewikkelde (bvb. geneste) combinaties van lijsten en tupels zijn die dus op hun beurt een rijke interne structuur kennen. Zo hebben we bijvoorbeeld een heel hoofdstuk gespendeerd aan de recursieve structuren die we m.b.v. zulke geneste tupels (en/of lijsten) kunnen bouwen.
Objecten kunnen we ook als datastructuren zien. Een object heeft immers attributen die op zich weer datawaarden bevatten. Net als een lijst of een tupel is een object dus letterlijk een structuur van data.
In tegenstelling tot lijsten en tupels gaat men bij het gebruik vanobjecten echter nog een stapje verder doordat de datastructuur weggestopt is achter een mooie naam, nl. de klassenaam van het object. Dat brengt ons bij het verschil tussen de begrippen datastructuur en datatype.
Datastructuren: zijn letterlijk structuren van data. Ze worden gebouwd door data aan mekaar te lijmen met behulp van een dataconstructietechniek zoals lijsten, tupels of klassen. De data die in de datastructuur samengelijmd zit kunnen atomair zijn of kunnen op hun beurt datastructuren zijn. Een datastructuur is ontleedbaar. In een lijst of tupel kan je bijvoorbeeld de onderdelen uitlezen d.m.v. indexering. In een object kan je de onderdelen uitlezen door de attributen van het object vast te pakken (met de syntax met het puntje).
Datatypes: zijn types van data. Herinner dat een type eigenlijk niet meer is dan een naam voor de desbetreffende verzameling. Dat kan een naam zijn voor een atomair datatype (bijvoorbeeld
int) of voor een datastructuur (bijvoorbeeldComplexofCannon) die uit meerdere componenten zijn opgebouwd.
Op ieder datatype zijn een aantal operatoren (en/of methoden)
gedefinieerd en je dient deze dan ook te gebruiken om de elementen van
het datatype te kunnen manipuleren. Voor atomaire datatypes als int is
dit uiteraard de enige manier omdat je de waarden ervan immers toch niet
kan ontleden in eenvoudigere onderdelen. Voor datastructuren kan dat wel
(t.t.z. je kan steeds indexering of attribuutselectie gebruiken). Maar
het louter gebruiken van de voorgeschreven operatoren en methoden heeft
als voordeel dat je niet hoeft te weten hoe de elementen precies
worden voorgesteld (lijsten, tupels, enz.). Je gebruikt gewoon de
methoden op een abstracte manier en de implementatie van het datatype
(t.t.z. de details van wat in de klasse zit) doet de rest. Dat hebben we
in de les over OOP uitvoerig laten zien met allerlei datatypes waarvan we niet eens wisten
hoe de implementatie eruit ziet. Zo hebben we bijvoorbeeld bij het gebruikt van nump
gezien dat je op een “matrix” de methode transpose kan oproepen om de
getransponeerde te berekenen zonder dat we daarvoor hoeven te weten
hoe die matrix intern wordt voorgesteld.
In dit hoofdstuk bestuderen we een aantal populaire datatypes die intern
weliswaar geconcipieerd zijn als datastructuur zonder ons hierbij af te
vragen hoe dat precies gebeurd is. We gebruiken enkel de voorgeschreven
operatoren en methoden. De focus van het hoofdstuk ligt op types waar
een collectieve datastructuur achter zit, t.t.z. een structuur die
dient om “collecties” van elementen bij te houden. De eenvoudigste
voorbeelden van collectieve datastructuren zijn lijsten en tupels. In
dit hoofdstuk bespreken we enkele bijkomende types die dikwijls nuttig zijn
zoals set (t.t.z.
verzamelingen,dictionary (t.t.z. woordenboeken) en file (t.t.z. bestanden). In dit hoofdstuk
bestuderen we deze enkel als abstractie en kijken we dus enkel hoe we de
methoden ervan correct dienen op te roepen. De interne implementatie
ervan is stof voor meer gevorderde cursussen.
We bestuderen twee groepen van datatypes waaraan telkens een andere soort van datastructuren ten grondslag ligt:
Interne datastructuren¶
zijn datastructuren die in het gewone werkgeheugen (het “RAM”) van onze computer zitten. Dit betekent dat ze nooit groter kunnen worden dan de hoeveelheid geheugen van onze computer. Het betekent ook dat deze datastructuren verloren zijn van zodra we de computer uitschakelen (of Python verlaten).
Externe datastructuren¶
zijn datastructuren die buiten het werkgeheugen van onze computer worden opgeslagen. Zulke datastructuren staan ook wel bekend als files. Ze “leven” op onze harde schijf en kunnen vele malen groter zijn dan het werkgeheugen. Denk maar aan enorme databanken van bedrijven als Google of Amazon of aan de enorme hoeveelheden data die ontstaan door alle gegevens van een ziekenhuis bij te houden. Een programma kan zulke data dan gedeeltelijk “inlezen” en er bewerkingen op uitvoeren. Externe datastructuren hebben naast het voordeel dat ze veel groter kunnen zijn dan het werkgeheugen ook het voordeel dat ze niet verloren gaan indien de computer wordt uitgeschakeld. Onze harde schijf onthoudt immers ook data zonder dat ze onder stroom staat.
Een overzicht van de datatypes die in dit hoofdstuk bestudeerd zullen worden is te vinden in onderstaande figuur.
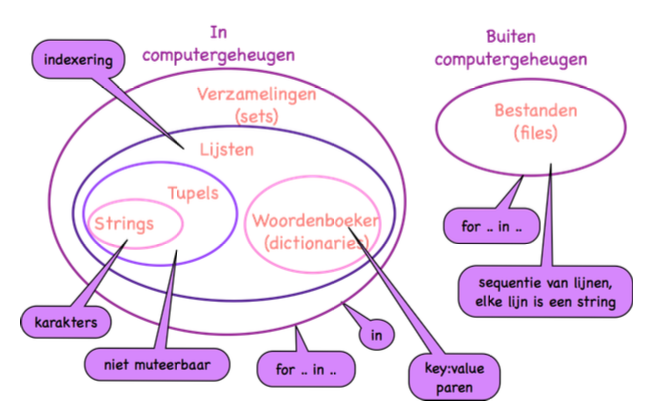
Verzamelingen (Sets)¶
We hebben reeds verschillende manier gezien om tupels en lijsten groter
te maken. Je kan bijvoorbeeld de + operator of de insert methode
gebruiken. Indien je in een bepaalde situatie echter zeker wenst te zijn
dat er in de resulterende structuur geen dubbels voorkomen dien je dat
zelf te programmeren (met de nodige if-tests). Eenvoudiger is echter
gebruik te maken van het ingebouwde type set.
Je kan een set aanmaken door een aantal waarden tussen accolades op te noemen. Je ziet ook dat een set in de REPL wordt uitgeprint met accolades. Bij het tweede voorbeeld zie je hoe de dubbels niet weerhouden worden.
test1 = {1, 2, 3}
test1
{1, 2, 3}
test2 = {1,3,4,2,5,1,3,4,2}
test2
{1, 2, 3, 4, 5}
Je kan ook werken via de constructor set. Die kan je
op verschillende manier gebruiken om een nieuwe verzameling aan te
maken en op te vullen met een aantal waarden. Onderstaande
expertimentjes illustreren de verschillende manieren. Je kan een tupel, een lijst of zelfs een string als argument geven. In het geval van een string is dat een verzameling met strengetjes van lengte \(1\).
test3 = set((5,3,7,4,7,3))
test3
{3, 4, 5, 7}
test4 = set([1,2,3])
test4
{1, 2, 3}
test5 = set('12321')
test5
{'1', '2', '3'}
Methoden op sets¶
sets zijn objecten waar allerlei nuttige methoden inzitten. Zoals steeds kan je met dir te weten komen welke methoden er precies voorhanden zijn. Hieronder illustreren we een greep uit de meest gebruikte. De methode difference neemt een tweede verzameling als
argument en berekent het verzamelingtheoretisch verschil van beide
verzamelingen. T.t.z. als \(A\) en \(B\) verzamelingen zijn, dan berekent
A.difference(B) de verzameling \(A \backslash B\). Analoog berekenen
A.union(B) en A.intersection(B) de verzamelingen \(A \cup B\) en
\(A \cap B\). Merk op dat deze methoden allen een nieuwe verzameling als uitkomst geven. Ook na het berekenen van de intersectie of unie zijn de verzamelingen kleintjes en oneven onveranderd.
cijfers = set(range(10))
kleintjes = set((0,1,2,3,4))
oneven = set((1,3,5,7,9))
cijfers
{0, 1, 2, 3, 4, 5, 6, 7, 8, 9}
kleintjes
{0, 1, 2, 3, 4}
oneven
{1, 3, 5, 7, 9}
kleintjes.difference(oneven)
{0, 2, 4}
kleintjes.intersection(oneven)
{1, 3}
kleintjes.union(oneven)
{0, 1, 2, 3, 4, 5, 7, 9}
oneven
{1, 3, 5, 7, 9}
kleintjes
{0, 1, 2, 3, 4}
De predicaten issubset en issuperset kan je gebruiken om
deelverzamelingen te testen. Dus levert A.issubset(B) True op als en
slechts als \(A \subset B\). issuperset test net het omgekeerde.
kleintjes.issubset(oneven)
False
cijfers.issuperset(oneven)
True
Tenslotte bespreken we de methoden waarmee je elementen kan toevoegen en
verwijderen uit verzamelingen. Dat zijn respectievelijk add en
remove. add garandeert hierbij natuurlijk dat er nooit dubbels in
een verzameling kunnen zitten. clear tenslotte roep je op als je een
verzameling leeg wil maken. Dat kan bijvoorbeeld nuttig zijn als je in
een lus iets aan het berekenen bent en je telkens van een lege
verzameling dient te vertrekken. Merk op dat deze methoden de set waarop je ze toepast wel aanpassen.
kleintjes.add(3)
kleintjes
{0, 1, 2, 3, 4}
kleintjes.add(5)
kleintjes
{0, 1, 2, 3, 4, 5}
kleintjes.remove(0)
kleintjes
{1, 2, 3, 4, 5}
kleintjes.clear()
kleintjes
set()
Woordenboeken¶
Sets, tupels en lijsten zal je gebruiken als je in een programma bepaalde datawaarden samen dient te houden. Denk bijvoorbeeld aan de lijst van spelitems die door een spel worden bijgehouden of aan de lijsten van variabelen en constanten in de Lindenmayersystemen die we bestudeerd hebben.
Voor sommige toepassingen hebben we meer nodig dan gewoon het bij elkaar houden van elementen. Denk bijvoorbeeld aan een verklarend of vertalend woordenboek. In zo’n woordenboek is het niet de bedoeling om gewoon woorden bij elkaar te houden. Dat zou niet erg handig zijn. Wel is het de bedoeling om de woorden te associëren met hun vertaling of verklaring. Een woordenboek is dus eigenlijk een grote verzameling koppels \((k,v)\) waarbij \(k\) het op te zoeken woord is en waarbij \(v\) de bijhorende vertaling of verklaring is. Het woordenboek is zodanig georganiseerd dat het makkelijk is om voor een gegeven \(k\) de bijhorende \(v\) snel te kunnen vinden.
In computerwetenschappen wordt dit idee veralgemeend:
Een dictionary is een datastructuur die een ongeordende muteerbaarde collectie van key-value paren bevat. De dictionary is zodanig georganiseerd dat voor een gegeven key snel de bijhorende waarde teruggevonden kan worden.
Hieronder volgt een voorbeeld. De variabele vogels wordt gedefinieerd
met een dictionary. Een dictionary wordt genoteerd door de elementen
ervan tussen accolades te noteren en te scheiden door komma’s. Ieder
element is van de vorm \(k:v\). In het voorbeeld hebben we dus twee
key-value paren. De eerste key is ’gans’ en de bijhorende
value is 3. De tweede key is ’eend’ en de bijhorende
value is 1. Deze dictionary drukt uit hoe dikwijls ieder type vogel
gezien is in een bepaalde regio.
vogels = {'gans' : 3, 'eend' : 1}
vogels
{'gans': 3, 'eend': 1}
De hele bedoeling van dictionaries is dat we nu op een heel comfortabele manier kunnen opzoeken welke value bij welke key hoort. Dat doen we door de ons welbekende indexeringsyntax te gebruiken. Doch, in de plaats van een getal te gebruiken als index, maken we gebruik van één van de keys. Dat zien we hieronder.
vogels['gans']
3
We gebruiken de indexeringsyntax ook om waarden te muteren.
vogels['eend'] = 7
vogels
{'gans': 3, 'eend': 7}
Net zoals we bij lijsten een foutmelding mogen verwachten indien de gebruikte index buiten het bereik van de lijst valt, krijgen we bij dictionaries een foutmelding indien de gebruikte key niet bestaat.
vogels['sneeuwgans']
---------------------------------------------------------------------------
KeyError Traceback (most recent call last)
<ipython-input-274-d474be5d7e0b> in <module>
----> 1 vogels['sneeuwgans']
KeyError: 'sneeuwgans'
Het muteren van een dictionary geeft echter automatisch aanleiding tot toevoegen van een key-value paar indien de gebruikte key niet reeds bestond. Dat wordt hieronder geïllustreerd:
vogels['sneeuwgans'] = 2
vogels
{'gans': 3, 'eend': 7, 'sneeuwgans': 2}
Ten slotte kunnen we het Python del sleutelwoord gebruiken om een
key-value associatie uit de dictionary weg te vegen.
del vogels['eend']
vogels
{'gans': 3, 'sneeuwgans': 2}
Omdat het indexeren met een niet-bestaande key een foutmelding geeft
is het handig een predicaat te hebben dat ons toelaat om op voorhand
te checken of een gegeven key al dan niet tot de dictionary behoort. In
Python wordt dit bewerkstelligd door het ... in ... predicaat.
Hieronder zien we twee voorbeelden:
'gans' in vogels
True
'eend' in vogels
False
Methoden op dictionaries¶
Net zoals sets zijn dictionaries objecten waar allerlei nuttige methoden
inzitten. Zoals steeds kan je met dir te weten komen welke methoden er
precies voorhanden zijn. Hieronder illustreren we een greep uit de meest
gebruikte.
Via de indexeringssyntax krijg je een foutmelding als de key niet bestaat. Met de get methode kan je ook opzoekingen doen in een dictionary. De get methode levert het verwachtte antwoord als de key bestaat en None als de key niet bestaat (de REPL print dan niets). je kan aan get een tweede argument meegeven en dan zal je die waardenterugkrijhen als de key niet bestaat.
wetenschappers = {'Newton' : 1642, 'Darwin': 1809, 'Turing' : 1912}
wetenschappers[Curie]
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
<ipython-input-282-331ac3558d20> in <module>
----> 1 wetenschappers[Curie]
NameError: name 'Curie' is not defined
wetenschappers.get('Darwin')
1809
wetenschappers.get('Curie')
wetenschappers.get('Curie', -999)
-999
De methoden update en clear ten slotte gebruiken we om dictionaries
te muteren “in één klap”. update voegt een meegegeven dictionary toe
aan een bestaande dictionary. Hierbij worden bestaande keys voorzien van
een nieuwe waarde in geval van dubbels. clear maakt een dictionary
leeg. Dat kan nuttig zijn indien de inhoud van een dictionary in een lus
wordt samengesteld en indien de lus telkens opnieuw met een lege
dictionary dient te beginnen.
temp = {'Curie' : 1867, 'Hopper' : 1906, 'Franklin' : 1920}
wetenschappers.update(temp)
wetenschappers
{'Newton': 1642,
'Darwin': 1809,
'Turing': 1912,
'Curie': 1867,
'Hopper': 1906,
'Franklin': 1920}
wetenschappers.clear()
wetenschappers
{}
Toepassing¶
Om het gebruik van dictionaries te illustreren grijpen we terug naar de tabel die we eerder in de cursus gebruikten en die laat zien welk aminozuur er bij ieder codon hoort in het proces van eiwitexpressie.
We hebben deze tabel toen geïmplementeerd met de volgende (verschrikkelijk lelijke) Python functie.
def aminoacid(triple):
if triple == "TTT" or triple =="TTC":
return "F"
elif triple in ("TTA","TTG","CTT","CTC","CTA","CTG"):
return "L"
elif triple in ("ATT","ATC","ATA"):
return "I"
elif triple == "ATG":
return "M"
elif triple in ("GTT","GTC","GTA","GTG"):
return "V"
elif triple in ("TCT","TCC","TCA","TCG","AGT","AGC"):
return "S"
elif triple in ("CCT","CCC","CCA","CCG"):
return "P"
elif triple in ("ACT","ACC","ACA","ACG"):
return "T"
elif triple in ("GCT","GCC","GCA","GCG"):
return "A"
elif triple in ("TAT","TAC"):
return "Y"
elif triple in ("TAA","TAG","TGA"):
return "STOP"
elif triple in ("CAT","CAC"):
return "H"
elif triple in ("AAT","AAC"):
return "Q"
elif triple in ("AAA","AAG"):
return "K"
elif triple in ("GAT","GAC"):
return "D"
elif triple in ("GAA","GAG"):
return "E"
elif triple in ("TGT","TGC"):
return "C"
elif triple == "TGG":
return "W"
elif triple in ("CGT","CGC","CGA","CGG","AGA","AGG"):
return "R"
elif triple in ("GGT","GGC","GGA","GGG"):
return "G"
else:
return None
Deze functie is niet alleen
lelijk maar ook nog zeer traag. Indien we ze oproepen met een gegeven
triplet dienen in het slechtste geval alle if-testen afgelopen te
worden. Dat kan veel mooier en sneller door de informatie uit de tabel
te coderen als een dictionary. Dat zien we hieronder. De dictionary
bevat een key-value paar voor elk mogelijk triplet. De value die bij een
triplet hoort is uiteraard het aminozuur.
aminoacidtable = { "TTT" : "F", "TTC" : "F",
"TTA" : "L", "TTG" : "L", "CTT" : "L", "CTC" : "L", "CTA" : "L", "CTG" : "L",
"ATT" : "I", "ATC" : "I", "ATA" : "I",
"ATG" : "M",
"GTT" : "V", "GTC" : "V", "GTA" : "V", "GTG" : "V",
"TCT" : "S", "TCC" : "S", "TCA" : "S", "TCG" : "S", "AGT" : "S", "AGC" : "S",
"CCT" : "P", "CCC" : "P", "CCA" : "P", "CCG" : "P",
"ACT" : "T", "ACC" : "T", "ACA" : "T", "ACG" : "T",
"GCT" : "A", "GCC" : "A", "GCA" : "A", "GCG" : "A",
"TAT" : "Y", "TAC" : "Y",
"CAT" : "H", "CAC" : "H",
"AAT" : "Q", "AAC" : "Q",
"AAA" : "K", "AAG" : "K",
"GAT" : "D", "GAC" : "D",
"GAA" : "E", "GAG" : "E",
"TGT" : "C", "TGC" : "C",
"TGG" : "W",
"CGT" : "R", "CGC" : "R", "CGA" : "R", "CGG" : "R", "AGA" : "R", "AGG" : "R",
"GGT" : "G", "GGC" : "G", "GGA" : "G", "GGG" : "G",
"CCT" : "STOP", "TAA" : "STOP", "TAG" : "STOP", "TGA" : "STOP" }
We kunnen nu indexering gebruiken om in de tabel te zoeken. Zo zal
bijvoorbeeld aminoacidtable["AGG"] de value "R" opleveren. Zonder in
detail te treden merken we op dat Python dat nagenoeg in \(O(1)\) doet. De
snelheid van het zoeken is dus (in tegenstelling tot de oplossing met de
lange if test) niet afhankelijk van de hoeveelheid gegevens die in de
dictionary vervat zitten.
aminoacidtable["AGG"]
'R'
Bestanden (Files)¶
Het laatste collectieve datatype dat we bestuderen zijn files (oftewel bestanden in correct Nederlands). In tegenstelling tot sets, lijsten, tupels en dictionaries zitten files niet in het werkgeheugen van Python maar wel op je harde schijf (op een moderne computer dikwijls al een Solid State Drive). Dat betekent dat de gegevens die erin opgeslagen zitten persistent zijn: indien de computer niet langer onder stroom staat blijven ze toch bewaard. De gegevens die in lijsten, tupels, sets of dictionaries zitten noemt men daarom volatiel. Indien we de Python REPL verlaten of indien de computer even de stroom verliest zijn we alles kwijt.
Abstract gesproken is een file een sequentie van strings. Deze noemen we
lijnen. Onderstaande figuur toont een zeer eenvoudige file die we in een
tekstverwerker hebben aangemaakt. De naam van de file is planets.txt.
Om files vanuit Python te kunnen manipuleren moeten we de file openen. Dit betekent dat Python de file op je harde schijf zal associëren met een Python object dat je in de REPL kan gebruiken. Je kan een nieuwe file maken door een file te openen voor “write”. Je kan een bestaande file uitbreiden door hem te openen voor “append” en je kan een bestaande file inlezen in het Python geheugen door hem te openen voor “read”.
Lezen van Files¶
Bestaande files kunnen worden geopend voor “read” om er vervolgens de gegevens uit te lezen (let op de file moet wel in de juiste folder staan; voor de cursusnota’s betekent dat dat de file in dezelfde folder moet staan als je notebook). De file op je harde schijf is nu geassocieerd met een heel speciaal Python object waarmee je in je programma aan de slag kan.
Door ’r’ (voor “read”) te gebruiken bij het openen van de file is de
file klaar om te lezen. Dat kunnen we doen door alle lijnen uit de file
af te lopen m.b.v. een for ... in ... constructie. Dat gebeurt dus op
precies dezelfde manier als de manier waarop we elementen in een lijst
aflopen. In bovenstaand voorbeeld printen we de lengte van elke lijn af
op het scherm. Elke lijn is een string, dus alle bewerkingen op strings die je kent kan je op een lijn toepassen.
data = open('planets.txt','r')
type(data)
_io.TextIOWrapper
for line in data:
print(len(line))
8
6
6
5
4
De resultaten van bovenstaand experiment verrassen je misshien. ‘Mercury” is maar 7 karakters, ‘Venus” maar 5, etc. Het cijfer is telkens 1 te hoog. Dikwijls bevatten de lijnen van een file allerlei ‘rommel’ voor en na de werkelijke gegevens. Dat kan gaan van spaties, tabs tot en met de “nieuwe lijn”-indicator, i.e. een onzichtbaar karakter dat je keyboard genereert als je op de “ga-aan-de-nieuwe-lijn” toets duwt op je toetsenbord en dat iha in een tekstfile een nieuwe lijn aankondigt.
Indien we op de
lijn (die dus gewoon een string is) de methode strip oproepen wordt
deze rommel verwijderd. Hieronder zien we hoe we de lengte berekenen van
de werkelijke data. In dit geval is dat de string zonder de “nieuwe
lijn”-indicator.
data = open('planets.txt','r')
for line in data:
print(len(line.strip()))
7
5
5
4
4
Merk nogmaals op dat files sequenties van lijnen zijn en dat lijnen
gewoon strings zijn. Dat wil dus zeggen dat we deze strings met de hand
moeten omvormen naar andere types indien nodig. Beschouw bijvoorbeeld de
file numbers.txt die we ook gewoon via een tekstverwerker hebben aangemaakt. We hebben bv. een aantal meetresultaten ingetikt.
Indien we deze file willen inlezen en indien
we de lijnen daadwerkelijk als getallen wensen te interpreteren, dan
dienen we deze met de hand te om te vormen. Bij de introductie van int en float hebben we laten zien dat
we waarden van andere types kunnen omvormen naar een getal door er de functies int of float op
toe te passen. Dat wordt gebruikt in onderstaand experiment waarin de
getallen van de file worden gelezen en opgeteld. Dat gebeurt door ze
één na één van de file in te lezen (als string) en de getalwaarde van de
string op te tellen bij de variabele sum. Kan je voorspellen welke
foutmelding je zou krijgen als je de oproep van float zou weglaten?
Probeer het uit!
data = open('numbers.txt','r')
sum = 0
for line in data:
sum = sum + float(line)
sum
73.5
Schrijven van Files¶
Hieronder zie je hoe je vanuit Python zelf een ‘verse’ file kan aanmaken. In dit experimentje openen we een nieuwe file met filenaam names.txt. De
’w’ (voor “write”) geeft aan dat we een nieuwe file willen maken om
data op te schrijven. Vervolgens gebruiken we de write methode om twee
strings naar de file te schrijven (merk op dat het speciale karakter
\n betekent “new line”). Ten slotte dienen we de file te sluiten
zodat Python ervoor kan zorgen dat alle inhoud ervan netjes en wel op de
harde schijf is opgeslagen.
outfile = open('names.txt','w')
outfile.write('wolfgang\n')
outfile.write('viviane\n')
outfile.close()
We kunnen deze file nu gaan bekijken door hem in onze favoriete tekstverwerker te openen. Dan zie je iets zoals in onderstaande figuur.
Naast het schrijven van gegevens naar een nieuwe file kunnen we ook
gegevens toevoegen aan een bestaande file.
Dit keer openen we de file met een ’a’ (voor “append”) als tweede
parameter. Alle oproepen van write zullen nu gegevens toevoegen aan de
bestaande gegevens die reeds op de file staan. In dit concrete geval
wordt de string ’Moon’ toegevoegd aan de eerdere planets.txt file.
myfile = open('planets.txt', 'a')
myfile.write('Moon')
myfile.close()
Het resultaat laten we zien in figuur.
Merk op dat we na het schrijven de file telkens netjes sluiten met een
oproep van de close methode. Dat is nodig omdat Python (omwille van de
snelheid) tussenliggende writes niet meteen naar de harde schijf
doorschrijft. Het is namelijk sneller op hardware niveau om een hele
serie van opeenvolgende strings in één keer weg te schrijven. Een oproep
van close dwingt Python om alle nog niet weggeschreven writes ook
effectief naar de schijf we te schrijven. Elke write die nadien nog op
de afgesloten file wordt opgeroepen zal een foutmelding veroorzaken.
Patronen om files te verwerken¶
De files die we tot nu toe gebruikten als voorbeeld waren wel zeer simpel. Ofwel stond er 1 woord op elke lijn ofwel 1 getal op elke lijn. ‘Echte’ files zijn meestal een stuk ingewikkelder. Hierna komen een aantal patronen aan bod die je moeten wapenen om met files die echte data en informatie bevatten om te gaan.
Files zijn meestal repetitief van aard. Dat wil zeggen dat er een herhaling van gelijkaardige data op staat. Zo kan een file bestaan uit een herhaling van numerieke metingen, een herhaling van chemische moleculen (die op zich bestaan uit atomen), een herhaling van studentengegevens (die elk op zich bestaan uit naam, adres, enz.), een herhaling van patiënten, enzovoort. Ieder “ding” in die herhaling noemen we een record. Soms past zo een record op 1 lijn maar heel vaak staat een record gespreid over de opeenvolgende lijnen. Vaak is het ook zo dat de eerste lijnen van een file een hoofding of wat commentaar bevatten eerder dan bv. meetdata.
Hoofdingen overslagen¶
Onderstaande figuur laat de inhoud van een vrij typische file zien.
We zien een hoofding die bestaat uit een aantal lijnen tekst die ons
wel interesseren indien we de file openen in een tekstverwerker maar die
ons niet interesseren zodra we de file willen gebruiken voor
automatische verwerking van haar data m.b.v. een Python functie. Stel
bijvoorbeeld dat we in Python een functie willen schrijven die de som
van alle punten weergeeft (bijvoorbeeld om nadien een gemiddelde te
berekenen). Onze file bestaat uit een titel, een aantal commentaarlijnen
(t.t.z. tekst voorafgegaan door een #) en vervolgens de numerieke
data. We zullen de file dan moeten inlezen op zodanige manier dat de
titel en de commentaarlijnen worden overgeslagen.
Alles hangt er van af of je weet hoe de file er uit ziet. Zijn er bijvoorbeeld altijd 3 lijnen die je mag overslagen en ben je dus zeker dat de data begint op lijn 4. Of is er een speciaal karakter zoals de # in het voorbeeld dat zegt dat een lijn ‘maar’ een commentaarlijn is.
Als je zeker weet dat je 3 lijnen mag skippen kan je volgend patroon gebruiken: je leest gewoon 3 lijnen waar je dan verder niets mee doet in skip_header. De rest van de file kan je met for ... in ... verder verwerken in de process_data functie.
def skip_header(rfile,n):
for i in range(1,n+1): rfile.readline()
def process_data(filename):
data = open(filename,'r')
skip_header(data,3)
totaal = 0
for line in data:
totaal = totaal + float(line)
data.close()
return totaal
process_data('punten.txt')
94.0
Als je niet zeker weet hoeveel lijnen je mag skippen zit je met een probleem. Je kan een file alleen maar lijn per lijn lezen. Je moet een lijn dus in zijn geheel lezen om dan te kunnen testen of ze al dan niet met een # begint. Maar dan heb je de eerste data lijn al gelezen vóór je je realiseert dat er geen "#" meer staat. Als je dan verdergaat met for ... in ... heb je een meting te weinig verwerkt.
Een standaard patroon is om de functie skip_header de laatst gelezen lijn (en dus de eerste data lijn) te laten teruggeven als een resultaat en die dan mee te verwerken zoals hieronder wordt geillustreerd.
def skip_header(rfile, ch):
rfile.readline()
line = rfile.readline()
while line.startswith (ch):
line = rfile.readline()
return line
def process_data(filename):
data = open(filename,'r')
line = skip_header(data, "#")
totaal = float(line)
for line in data:
totaal = totaal + float(line)
data.close()
return totaal
process_data('punten.txt')
94.0
Ongeldige Data Overslaan¶
Het feit dat we de ingelezen strings naar een float converteren maakt
onze voorbeelden kwetsbaar. Indien we een file inlezen met lijnen erop die
geen correcte stringrepresentaties zijn van een getal zal de functie
falen. Beschouw bijvoorbeeld de file uit onderstaande figuur.
Hier heeft de professor gekozen om een
streepje te gebruiken voor de studenten die niet zijn komen opdagen voor
het examen. Indien we process_data op deze file loslaten zal het
uiteraard mislopen. Een streepje kan niet naar een float worden
omgevormd:
process_data('punten-bis.txt')
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
<ipython-input-317-65b20fb32e50> in <module>
----> 1 process_data('punten-bis.txt')
<ipython-input-315-f5f7905994a2> in process_data(filename)
4 totaal = float(line)
5 for line in data:
----> 6 totaal = totaal + float(line)
7 return totaal
ValueError: could not convert string to float: ' -\n'
Dat kunnen we uiteraard voorkomen door onze functie stabieler te maken
door haar te wapenen met een if test vóór we proberen van een lijn om te vormen naar een getal. Merk op dat we dat in deze code op twee plaatsen moeten doen omdat het ook de eerste student kan zijn die afwezig was.
def process_data(filename):
data = open(filename,'r')
line = skip_header(data, "#")
if line == '-':
totaal = 0
else:
totaal = float(line)
for line in data:
line = line.strip()
if line != "-":
totaal = totaal + float(line)
data.close()
return totaal
process_data('punten-bis.txt')
80.0
Gecombineerd Gebruik van Datatypes¶
Tot nu toe was de data die op de file stond vrij eenvoudig. Ieder record is gewoon een getal (of een streepje om de afwezigheid van een getal aan te duiden). Het “verwerken” van de data bestond gewoon uit het optellen van al deze getallen. Maar een file kan echter veel meer betekenis in zich dragen.
Bekijk bijvoorbeeld de file die getoond wordt in onderstaande figuur Ze is ontstaan doordat een vogelspotter in zijn tekstverwerker telkens de naam heeft toegevoegd van zijn meest recent gespotte vogel.
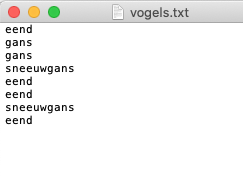
Stel dat we willen weten welke de (verschillende) vogelsoorten zijn die op de file staan. Dat doet process_birdshieronder. In plaats van zélf ingewikkelde machinerie op poten te zetten om met
dubbels op de file om te kunnen gaan maken we handig gebruik van het
set type. De lijn birds = set() maakt een lege verzameling aan.
Vervolgens lopen we de inhoud van de file af en voegen we iedere geziene
vogelnaam toe aan de verzameling met add. Zoals eerder uitgelegd
worden in verzamelingen sowieso geen dubbels opgeslagen wat dus exact
ons probleem oplost. We eindigen door de file netjes af te sluiten en de
opgebouwde verzameling birds terug te geven uit de functie. Hier zien
we de functie aan het werk:
def process_birds(filename):
data = open(filename, "r")
birds = set()
for line in data:
name = line.strip()
birds.add(name)
data.close()
return birds
process_birds('vogels.txt')
{'eend', 'gans', 'sneeuwgans'}
Stel dat we willen tellen hoe dikwijls elke vogelsoort in de file voorkomt. Dat kunnen we heel eenvoudig
bewerkstelligen door een dictionary te gebruiken in de plaats van een
set. process_birds_bis is een variant op process_birds die dit doet. Ze begint met een lege dictionary
birds. Vervolgens worden de lijnen één voor één ingelezen en worden de
overeenkomstige vogelnamen gebruikt om in de dictionary te indexeren.
Herinner dat (nog) niet bestaande keys automatisch worden toegevoegd bij
mutatie. De keys in de dictionary zijn zoals gezegd de volgelnamen. De
bijhorende values zijn getallen die bijhouden hoeveel keer de naam in de
file werd gezien.
def process_birds_bis(filename):
data = open(filename, "r")
birds = {}
for line in data:
name = line.strip()
if name in birds:
birds[name] = birds[name]+1
else:
birds[name] = 1
data.close()
return birds
process_birds_bis("vogels.txt")
{'eend': 4, 'gans': 2, 'sneeuwgans': 2}
Meerdere Records per Lijn¶
Tot nu toe zijn we ervan uitgegaan dat elke lijn precies één record bevat (een punt of een vogelsoort) eventueel voorafgegaan en gevolgd door wat spaties. Dat hoeft uiteraard niet zo te zijn. De file in onderstaande figuur bevat op elke lijn meerdere punten die gescheiden zijn door spaties.
Stel dat je nu alle getallen op de file wil samentellen.
Deze moeilijkheid gaan we opnieuw te lijf met procedurele abstractie. We
schrijven een functie process_data die over de verschillende lijnen
zal itereren. In elke slag van de iteratie roepen we de functie
process_one_line op die om zal gaan met de verschillende punten op één
lijn. process_one_line krijgt een lijn als parameter binnen. Door de
methode split op te roepen zal deze lijn (t.t.z. een string)
geconverteerd worden in een lijst van strings. Deze strings ontstaan
door de originele string te splitsen bij de spaties. Door met een for
lus over deze lijst te lopen kunnen we makkelijk het subtotaal van één
lijn berekenen. process_data past deze functie dan op iedere ingelezen lijn toe.
def skip_header(rfile, ch):
rfile.readline()
line = rfile.readline()
while line.startswith (ch):
line = rfile.readline()
return line
def process_one_line(line):
subtotal = 0
for value in line.split():
subtotal = subtotal + float(value)
return subtotal
def process_data(filename):
data = open(filename, "r")
line = skip_header(data, "#")
total = process_one_line(line)
for line in data:
total = total + process_one_line(line)
data.close()
return total
process_data('meer-punten.txt')
460.5
Records met Meerdere Velden¶
Tot nu toe zijn we ervan uitgegaan dat ieder record in de file uit één gegeven (bijvoorbeeld een string of een getal). Maar dat is meestal niet zo. Zo zal iedere patient in een ziekenhuisadministratie verschillende gegevens bevatten zoals zijn naam, zijn voornaam, de redenen van de verschillende bezoeken aan het ziekenhuis, de lijst van medicijnen die hij ooit gekregen heeft enzovoort. In een bibliotheeksysteem zal ieder boek opgeslagen zijn als een combinatie van de auteur, titel, jaar van uitgave, ISBN nummer, enzovoort. Zulke samengestelde records zijn opgebouwd uit wat men velden noemt. In onderstaande figuur zien we een file die studentengegevens bevat. Ieder record (m.a.w. iedere student) bestaat uit 4 velden: de naam, de voornaam, het gemiddeld aantal punten dat de student behaald heeft en het aantal geregistreerde studiepunten. In dit voorbveeld staat elk record netjes op 1 lijn.
In wat volgt schrijven we een Python functie om deze file te verwerken zodat we op het einde een tupel krijgen met daarin het gemiddelde gemiddelde en het gemiddeld aantal opgenomen studiepunten van alle studenten die op onze file staan.
process_students initialiseert drie variabelen: total zal gebruikt
worden om alle gemiddeldes bij elkaar op te tellen, totalSP zal
gebruikt worden om alle opgenomen studiepunten bij elkaar te tellen en
count zal gebruikt worden om het aantal gelezen records te tellen. Dat
laatste is nodig om op het einde gemiddeldes
te berekenen.
Een bijzonder handig hulpmiddel bij het verwerken van de samengestelde
records is de meervoudige assignment van Python. Hierbij zetten we links
van het = verschillende variabelen en rechts een tupel of een lijst.
In één klap worden dan aan alle variabelen een waarde toegekend die
overeenkomt met de corresponderende positie in de lijst of in het tupel.
def process_students(filename):
data = open(filename, "r")
total = 0
totalSP = 0
count = 0
for line in data:
firstname, lastname, average, sp = line.split()
total = total + float(average)
totalSP = totalSP + int(sp)
count = count + 1
data.close()
return (total / count, totalSP / count)
process_students('studenten.txt')
(13.563999999999998, 60.2)
In onze functie lezen we lijn per lijn in m.b.v. de for. Iedere lijn
is een record dat uit 4 velden bestaat. Door split op te roepen
converteren we de string naar een lijst van strings. Deze elementen van
deze lijst worden dan via een meervoudige toekenning aan de 4 tijdelijke
variabelen (firstname, lastname, average en sp) toegekend. De
laatste 2 worden vervolgens geconverteerd naar een float om bij de
geaccumuleerde totalen te tellen. De count variabele wordt met 1
verhoogd in elke slag van de iteratie (m.a.w. bij het inlezen van ieder
record). Na de iteratie wordt de file afgesloten en worden de 2
gemiddeldes in een tupel uit de functie teruggegeven.
Data op Vaste Posities¶
De files die we tot nu toe gezien hebben waren redelijk goed leesbaar voor mensen doordat de data mooi geordend is over verschillende lijnen en doordat de data gescheiden werd door spaties of tabs. Soms is dat niet het geval en zit alle data vlak bij mekaar geplakt op vast afgesproken posities in de file. Dat is dikwijls zo indien de file automatisch gegenereerd werd door een programma of door software die in één of andere machine zit. Bekijk bijvoorbeeld de file in onderstaande figuur, Deze file bevat verschillende records die elk op een lijn staan. Op het eerste zicht zijn alle records gewoon getallen. In dit geval hebben de records echter een andere betekenis:
De eerste 7 cijfers van iedere lijn vormen een datum in “DDMMYYYY” formaat.
De volgende 3 cijfers bevatten de temperatuur die gemeten werd op die datum in de vorm van een
floatdie eruit ziet als “ff.f”.De volgende 2 cijfers vormen de luchtvochtigheidsgraad in de vorm van een percentage. Dat is een getal van de vorm “ff”.
De laatste 4 cijfers zijn van de vorm “ffff” en stellen de gemeten luchtdruk voor in millimeter kwik (t.t.z. in mmHg).
We zullen deze file inlezen en in de REPL tonen op het scherm. We gaan
opnieuw procedure abstractei gebruiken: process_data zal de file lijn
per lijn inlezen en process_one_line oproepen voor iedere lijn. Deze
zal de lijn dissecteren volgens bovenstaande opdeling. Eigenlijk is hier
helemaal niks moeilijk aan. De lijn is een string en we weten dat
lijsten en strings makkelijk met slicing
“gedissecteerd” kunnen worden. Zo halen we bijvoorbeeld de temperatuur
uit de string m.b.v. de slice line[8:12] aangezien we de twee cijfers
op posities 8 en 9, het puntje op positie 10 en het cijfer op positie 11
nodig hebben. Deze string van lengte 4 wordt dan door een oproep van
float naar een getal geconverteerd. In de functie converteren we de
overige stukken string naar een geheel getal. Merk op dat we een 2-tupel
teruggeven uit de functie. De eerste component is een 3-tupel dat de
datum voorstelt en de tweede component is een 3-tupel dat de
temperatuur, de vochtigheidsgraad en de druk bevat.
def process_one_line(line):
day = int(line[0:2])
month = int(line[2:4])
year = int(line[4:8])
temp = float(line[8:12])
hum = int(line[12:14])
pres = int(line[14:18])
return ((day,month,year),(temp, hum, pres))
process_data is nu vrij triviaal. We overlopen de inhoud van de file
en we vergaren alle aldus ingelezen tupels in een lijst. Deze lijst
wordt na het afsluiten van de file teruggegeven uit de functie. Zo heb je de data beschikbaar in een lijst om er verdere bewerkingen op te doen.
def process_data(filename):
data = open(filename, "r")
result = []
for line in data:
result.append(process_one_line(line))
data.close()
return result
process_data('waarnemingen.txt')
[((1, 8, 2010), (22.0, 30, 1010)),
((2, 8, 2010), (20.5, 35, 1015)),
((3, 8, 2010), (19.8, 60, 999)),
((4, 8, 2010), (21.2, 45, 1012))]
Records over Meerdere Lijnen¶
We hebben reeds files gezien met precies één enkelvoudig record per lijn
(bijvoorbeeld één getal per lijn), met meerdere enkelvoudige records per
lijn, en met één samengesteld record per lijn (bijvoorbeeld een student
per lijn). De moeilijkste files om in te lezen zijn files waarbij we
samengestelde records hebben die over verschillende lijnen verspreid
zitten. Onderstaande figuur toont zo’n file. Ieder record is de
beschrijving van een samengestelde molecule. Ieder record begint met de
string COMPND en eindigt met de string END zodat we precies kunnen
weten welke gegevens bij welk record horen. Deze twee strings vormen als
het ware het “haakje open” en het “haakje dicht” van het record. Meteen
na COMPND volgt er op dezelfde lijn een string die de naam van de
samengestelde molecule voorstelt. Op de hieropvolgende lijnen volgen dan
de atomen die de molecule vormen.
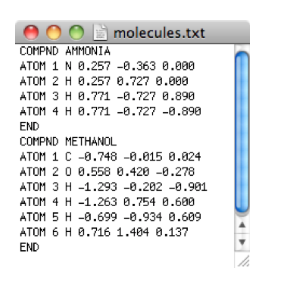
We zullen opnieuw procedurele abstractie gebruiken om het probleem aan
te pakken: we schrijven eerst een procedure read_molecule die probeert van 1 enkele molecule van de file te lezen. Als dat niet lukt zal de functie None teruggeven. We beginnen met het inlezen
van één lijn. Indien hier meteen None uit komt weten we dat er geen
data meer voorhanden is en geven we None terug. Anders splitsen we de
ingelezen lijn op in twee onderdelen. Het eerste onderdeel is het
sleutelwoord COMPD en het tweede onderdeel is de naam van de molecule.
Vervolgens beginnen we een iteratie die alle atomen blijft inlezen
zolang het END sleutelwoord niet gezien is. Hier gebruiken we een standaard patroon blijven lezen tot je een afgesproken sleutelwoord tegenkom. Dat gebeurt door een soort controlevariabele te introduceren die in het begin op True staat. Maar als het sleutelwoord wordt gelezen wordt die variabele op False gezet.
Dat gebeurt in read_moleculemet de variabele reading.
De molecule zelf is
een Python lijst. De eerste component is de naam van de molecule (een
string dus) en de eropvolgende componenten zijn de atomen. Ieder atoom
is een 4-tupel dat bestaat uit de atoomsoort, en de ruimtelijke (X,Y,Z)
coördinaten van het atoom binnen de molecule. In de file wordt een atoom
echter voorafgegaan door de string ATOM en het rangnummer van het
atoom in de lijst. De 6 strings die aldus de lijn vormen worden na de
oproep van split door een meervoudige assignment in 6 lokale Python
variabelen opgevangen.
def read_molecule(rfile):
line = rfile.readline()
if not line:
return None
key, name = line.split()
molecule = [name]
reading = True
while reading:
line = rfile.readline()
if line.startswith('END'):
reading = False
else:
key, numb, typ, x, y, z = line.split()
molecule.append((typ, x, y, z))
return molecule
Nu kunnen we beginnen aan read_all_molecules. Die gaat in een iteratie telkens een volgende molecule proberen te lezen. Je ziet hier een tweede standaard patroon aan het werk nml. blijven doorgaan tot het niet meer lukt. Dat gebeurt opnieuw door reading als een soort controlevariabele te introduceren die in het begin op True staat. Maar als het lezen van een volgende molecule niet meer lukt, wordt die variabele op False gezet.
Dus read_all_molecules opent de file, en gaat meteen
een iteratie in die blijft doorlopen zolang er molecules ingelezen
worden. Telkens opnieuw proberen we een molecule in te
lezen door read_molecule op te roepen. Deze zal een molecule
teruggeven (in de vorm van een 4-tupel) of None indien er geen
molecules meer voorhanden waren. De eropvolgende if test kijkt dit na.
Indien er een molecule gelezen werd, voegen we ze toe aan de
resultaatlijst die wordt opgebouwd. Anders zetten we reading op
False waardoor de iteratie beëindigd wordt. De file wordt tenslotte
afgesloten en de resultaatlijst wordt teruggegeven. Je kan nu de informatie in de lijst verder verwerken in de rest van je programma.
def read_all_molecules(filename):
input_file = open(filename, "r")
result = []
reading = True
while reading:
mol = read_molecule(input_file)
if mol:
result.append(mol)
else:
reading = False
input_file.close()
return result
read_all_molecules('molecules.txt')
[['AMMONIA',
('N', '0.257', '-0.363', '0.000'),
('H', '0.257', '0.727', '0.000'),
('H', '0.771', '-0.727', '0.890'),
('H', '0.771', '-0.727', '-0.890')],
['METHANOL',
('C', '-0.748', '-0.015', '0.024'),
('H', '-1.293', '-0.202', '-0.901'),
('H', '-1.293', '0.754', '0.600'),
('H', '-0.699', '-0.934', '0.609'),
('O', '0.558', '0.42', '-0.278'),
('H', '0.716', '1.404', '0.137')]]
In dit voorbeeld hebben we laten zien hoe while moet gebruikt worden
om een file in te lezen (of om één record in te lezen) waarvan we op
voorhand niet weten hoeveel data er nog komt. Lijn na lijn wordt
ingelezen. In het ene geval wordt de iteratie afgebroken zodra we het
sleutelwoord END zien. In het andere geval wordt de iteratie
afgebroken van zodra er geen data meer voorhanden is op de file.
Samenvatting¶
We hebben reeds allerlei types bestudeerd die zijn ingebouwd in de taal Python. Voorbeelden hiervan zijn getallen, strings, lijsten, tupels. Na het bestuderen van de rijkere objectgerichte syntax hebben we in dit hoofdstuk onze kennis van de ingebouwde types uitgebreid met drie nieuwe telgen: verzamelingen, woordenboeken en bestanden. We hebben gezien wat de belangrijkste methoden zijn die we op elk van deze drie types kunnen toepassen.
Naast dit theoretisch gedeelte hebben we ook heel wat technieken laten zien om files op te bouwen en in te lezen. De records die in een file zitten kunnen enkelvoudig of samengesteld zijn. Samengestelde records bestaan uit verschillende velden. Enkelvoudige records kunnen elk op een aparte lijn voorkomen of er kunnen meerdere records per lijn opgenomen zijn. De velden van samengestelde records kunnen op 1 enkele lijn voorkomen maar kunnen ook over verschillende lijnen verspreid zijn. Voor al deze technieken hebben we laten zien hoe procedurele abstractie kan gebruikt worden om de complexiteit van het inleesprogramma onder controle te houden.